2024 年绝对可以说是 AI 大模型的元年,尤其年底这几个月,没想到迎来了各种AI 科技大爆发。
先是Claude mcp 协议的发布,极短的时间就迎来了各种 mcp server 的发布,整个生态蓬勃发展。OpenAI 紧随其后,也发布了自己的 Sora模型,以及其他的一些更新和特性,但是 OpenAI 的 12 天活动似乎有点噱头,到第四五天就没有什么亮点了。12 天还没结束,没想到谷歌的 Gemini 2.0 抢了风头,成了那个最亮的星。
Gemini 突然爆火是我没有想到的,上一次用可能还是去年,体验感觉让人一言难尽。这次看到大家都说它真的很强,多模态,忍不住也来体验一番,看看是不是说的那么回事。
谷歌跟其他 AI 大模型的风格貌似有点不太一样。目前最新发布的在其 https://gemini.google.com/ 上面,并不能体验到。需要到 Google AI Studio 上面才能体验到这次发布的重点更新,Google AI Studio 也就是 Google 主要用于快速测试和学习 AI 模型的平台。
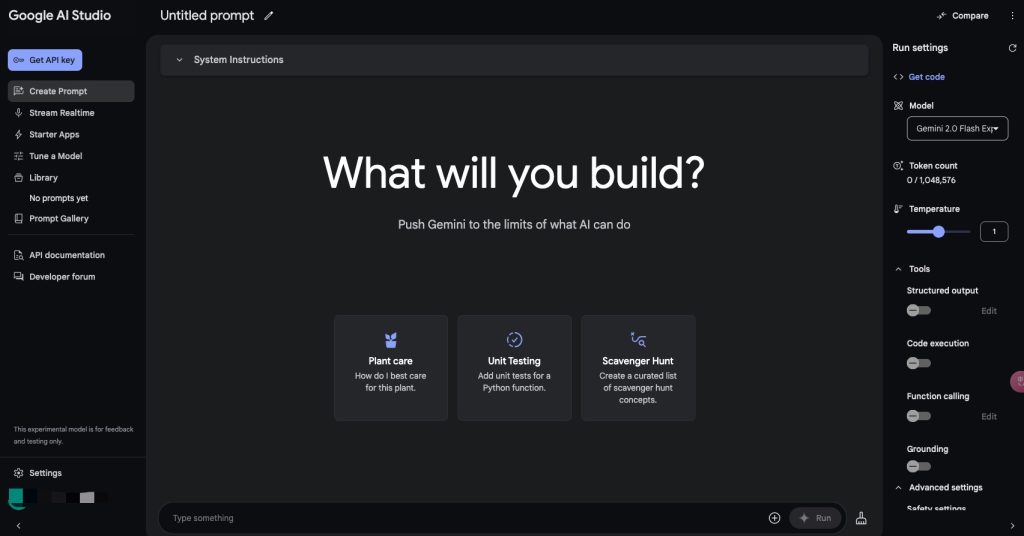
在 Google AI Studio 上面,不仅可以直接对各种模型进行测试,也可以获取 API key,通过程序调用 API 接口进行使用,非常简单方便。
在 Google AI Studio 的左侧菜单栏,分为 Create Promote、Stream Realtime、Starter Apps、Tune a Model 一级 library 等其他选项。Create Promote 支持目前 Gemini 所有的模型选择,并且可以进行参数调节、工具选择的功能。而 Stream Realtime 目前只支持Gemini 2.0 Flash Experimental 模型,这个模型也是这次发布最大的亮点。
谷歌不愧是谷歌,相比其他模型也显得相当的大方。目前最先进的 Gemini 2.0 模型,也有这相对比较大量的免费使用额度。

从图中可以看到,目前 Gemini 2.0 是免费的,每分钟调用限制为 10 次,每天最多 1500 次。如果正常一个人来说使用,那是非常大的用量了。当然,谷歌的目的应该还是让一些应用进行API 接口调用测试吧。 Gemini 2.0 支持处理 10000 行代码,可以支持调用原生工具,比如搜索。
除了 Gemini 2.0 , 所有当前正式的模型,包括 Gemini 1.5 pro,都有一定的免费额度。比如如下图的 Gemini 1.5 pro 模型用量。
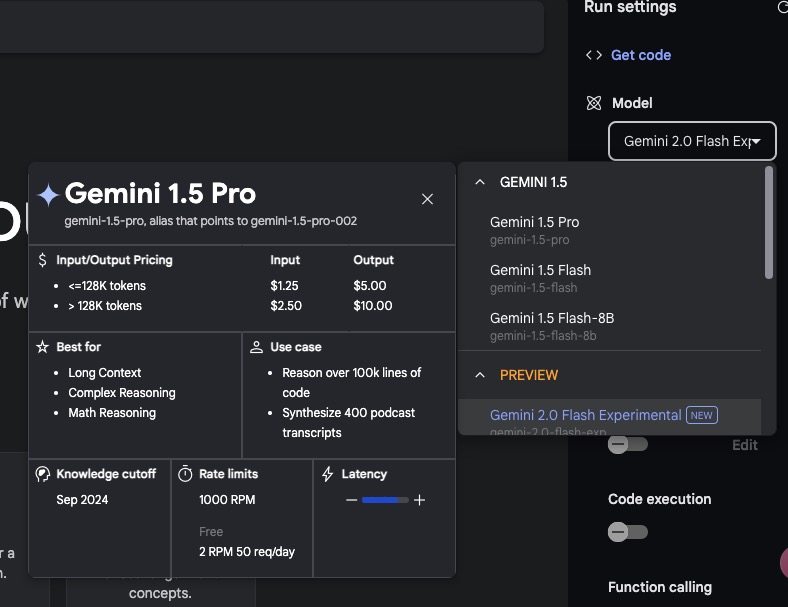
Gemini 1.5 Pro 每天的用量比较少,而 Gemini 1.5 Flash 和 1.5Flash-8B的免费额度则分别每天都有 1500 次的使用额度。
接下来我们说回到重点 Gemini Stream Realtime。 目前只有 Gemini 2.0 Flash Experimental 模型支持 Stream Realtime。它的输出方式可以选择语音和文本,如果选择语音输出的话,也可以对应5 种声音可以选择。 而输入的方式则比较有趣,可以选择语音、视频,而视频输入则可以选择是使用摄像头还是分享自己的屏幕。

看到这里的时候,有些人可能觉得这么有什么。ChatGPT 的高级语音就一直可以进行语音对话等,体验还相当不错。我刚开始也这么觉得,后来发现我是真的没有想到目前 AI 大模型可以发展的这么快。
目前,大多数的大模型语音对话的原理,都是将用户的声音通过语音识别转文文字,最终跟大模型进行对话交流的本质上来讲还是文本。 这样就有一个问题,虽然是语音对话,但是 AI 大模型是不能分辨出你的发音是什么的,不过Gemini 2.0 这里似乎是有了很大的改观。 它可以识别出我的发音状况,并且可以识别出很多其他的声音,比如识别出了孩子吵闹的嘈杂音,还可以识别出咳嗽声音等其他各种声音。

Gemini 可以识别比分析你的发音,但是只是针对英语,中文的话,我实测它并没有真正地分辨出你的发音准确性,因为你无论如何发音它都不会识别出来你声调的错误。 中文的支持应该还需要时间,目前Gemini 可以听到并且准确识别听懂中文,但是 Audio 目前不支持中文,如果让它去说中文,它会说出奇怪的声音,但是文字倒是没有问题的。
使用 Gemini 2.0 进行英文对话,非常地丝滑,你可以跟使用 ChatGPT 地高级语音一样,随意地去打断,并且响应速度也很快,很快就可以给出回答。看来 Gemini 2.0 可以完全代替 ChatGPT 高级语音进行英语口语对话练习的角色了。
视频实时输入也是另一个非常有用的功能。真正实现了结对编程,或者像找一个位一对一的老师来实时指导的感觉。其实我觉得这个功能与编程指导相比较,对于一些操作类的东西,或者其他场景更加有用,毕竟编程是需要更多的代码上下文才能有更多的理解,而屏幕截图可能只是部分内容。
比如针对可以开发一款眼镜,接入 Gemini,给盲人使用,实时进行看到的画面解说,并且可以通过语音进行对话更加细节的内容询问。实现显示世界中Netflix 电影旁白的功能,应该会极大的提高盲人的幸福指数吧。当然应该也有更多的场景,比如作为普通人的日常生活助理,随时对看到的和听到的内容进行更加细致地交流。
目前甚至创建了一个 github 项目,包含代码以及具体的一些实例,包括视频分析器、空间理解、地图探索者。 可以根据照片,结合 2d 和 3d 的空间分析进行推理,指出物体、文本的位置。视频分析器可以总结、描述场景,还可以提取文本搜索对象等。Gemini 可以结合 Google Maps API 探索更多有趣的地方。

许多人通过使用谷歌的 python 代码示例,也做出了很多有趣的功能。
应该用不了多久,会有更多更加有趣的基于 Gemini 的实际应用发布,也有更多的实际应用场景来改变我们的生活吧。